பாகம் 15ல் திரு G. ராஜாராமன், சவுதி அரேபியா அவர்கள் கீழ்க்கண்ட கேள்வியை எழுப்பி இருந்தார். அவருக்கு விடையளிக்கும் விதமாக இந்தப்பதிவு அமைகிறது.
இதன்மூலம் Front End, back end போன்றவற்றைத் தெரிந்துகொள்வதுடன் அவை எதற்காகப் பயன்படுகின்றன என்பதையும் அறிந்துகொள்வீர்கள்.
அவர் கேட்ட கேள்வி :
மிகவும் அழகாக தொடரை வழங்கிக் கொண்டு இருக்கின்ற நண்பருக்கு மிக்க நன்றி. நண்பரே எனக்கு ஒரு சந்தேகம் உள்ளது. அதனை தாங்கள் தீர்ப்பீர்கள் என நம்புகிறேன்.
எனது அலுவலகத்தில் Inventory Sotware பயன்படுத்துகின்றனர். இந்த Inventory sotware ஐ கணிப்பொறியில் C அல்லது D ஏதேனும் ஒரு கோலனில் ( partition) copy & paste செய்துள்ளனர். பிறகு இதற்க்காக oracle developer 6i மற்றும் Power builder 5 ஐ install செய்துள்ளனர். பிறகு Paste செய்துள்ள Inventory software ல் உள்ள inventory.exe எனும் file ஐ click செய்தாள் inventory வேலை செய்கிறது. மேலும் இதன் மூலம் உள்ளீடு செய்யப்படுகின்ற தகவல் அனைத்தும் எங்கள் அலுவலகத்தில் தனியாக வைத்துள்ள server ல் பதிவாகிறது. இந்த Inventory software ஆனது network ல் system ல் மட்டும் வேலை
செய்கிறது.
எனது சந்தேகம் Oracle, Power Builder மற்றும் எங்களது Inventory software இவை மூன்றுக்கும் என்ன தொடர்பு?
எங்கள் அலுவலகத்தில் Inventory software எந்த software பயன்படுத்தி Create பண்ணியுள்ளனர். மேலும் நாம் பார்துவரும் sql serverக்கும் நான் மேலே கூரியவைகளுக்கும் ஏதேனும் தொடர்பு உள்ளதா? sql server ஐ பயன்படுத்தி table மட்டும் தான் create பண்ணமுடியுமா அப்படியன்றாள் MS-Access ஐ பயன்படுத்தியே இதனை செய்யலாமே, மேலும் sql server ல் Inventory software ஐ உருவாக்கமுடியுமா?
நண்பரே நான் எழுப்பியுள்ள சந்தேகத்தை நீங்கள் தீர்ப்பீர்கள் என அதனை நான் இங்கே வைத்துள்ளேன்.
நன்றியுடன்,
G. ராஜாராமன், சவுதி அரேபியா
இனி எனது பதில் :
Inventory Software ஐ Power Builder பயன்படுத்திச் செய்து Inventory.EXE ஐ உருவாக்கி இருப்பார்கள்.
அதன் முகப்புத்தோற்றங்கள் அனைத்தையும் Power Builder வழியாக எளிதாகச் செய்திருப்பார்கள்.
Power Builder, Visual Basic போன்றவற்றை Front End Tools என்போம். நீங்கள் அந்த பயன்பாட்டை இயக்கும்போது உங்கள் கண்முன்னே தெரியும் Textbox, combobox, Grid, dialog box இப்படி என்னவெல்லாம் கண்முன் தெரிகிறதோ அவையனைத்தையுமே ஒரு Front End ஐ வைத்தே உருவாக்கி இருப்பார்கள்.
உங்களிடம் இருந்து User Name, Password ஆகியவற்றை வாங்குவதற்காக உங்கள் கண்முன் தெரிகிறதே TextBox இவற்றை உருவாக்க உதவுவது Front End Tool.
ஆனால் உங்கள் User Name, Password போன்றவை எங்கே பதிவாகி இருக்கும்? அது ஒரு Back End ல் பதிவாகி இருக்கும். Back End tool க்கு உதாரணம்தான் Oracle, Sybase, MySQL, SQL Server எல்லாம்.
உங்களிடமிருந்து தகவலை வாங்குவதற்கு உதவும் முகப்புத்திரைகளை Front End Tool வாயிலாகச் செய்தபின், தகவல்கள் அனைத்தையும் பதிந்து வைப்பதற்காக Back End பயன்படுகிறது.
உங்கள் கணினியில் Power Builder இனிமேல் தேவைப்படாது. எப்போது? எந்தத் தவறுகளும் இல்லாத ஒரு Application ஐ உருவாக்கிய பிறகு அதன் Codings அனைத்தையும் சுருக்கி ஒரே கோப்பாகவோ, அல்லது Installation Package ஆகவோ கொடுப்பார்கள்.
அந்த Installation Package அல்லது ஒரு EXE ஐ வேறு ஒரு கணினியில் நிறுவியபிறகு (Install) Front End Tool தேவைப்படாது (உங்கள் கருத்துப்படி Power Builder).
ஆனால் அனைத்துத்தகவல்களையும் உங்கள் கருத்துரைப்படி Oracle ல் பதிவதால் Oracle கண்டிப்பாக Install செய்யப்பட்டு இருக்கவேண்டும்.
எப்போதெல்லாம் பழைய தகவல்கள் தேவைப்படுகிறதோ, அப்போதெல்லாம் அந்த EXE ஆனது Database உடன் தொடர்புகொண்டு தகவல்களை எடுத்துக்கொண்டுவந்து திரையில் காண்பிக்கும்.
எனது சந்தேகம் Oracl, Power Builder மற்றும் எங்களது Inventory software இவை 3 ற்க்கும் என்ன தொடர்பு?
நன்றாக நினைவில் கொள்ளவும் :
1) கண்முன்னே காணப்படும் திரைகளை, திரையில் தெரியும் தகவல்கள் அல்லாத பிற அம்சங்களை உருவாக்கத்தான் Power Builder.
2) Inventory.exe ஐ இயக்கியபிறகு அது கேட்கும் தகவல்களை நீங்கள் கொடுப்பீர்கள். அல்லது நீங்கள் கேட்கும் தகவல்களை அது கொடுக்கும். ஆக அனைத்துத்தகவல்களும் உங்களுடைய Oracle databaseல் இருந்துதான் வருகிறது.
3) எதை நீங்கள் பதிந்தாலும் உங்களது Oracleல் தான் பதிவாகும்.
4) எதை நீங்கள் எடுத்தாலும் உங்களது Oracleல் இருந்துதான் எடுப்பீர்கள்.
Inventory.EXEஐ உருவாக்கிய பிறகும் எதற்காக மீண்டும் PowerBuilder ஐ நிறுவுகிறார்கள்.
இந்த Application ல் எந்த விதமான பிழைகளும் இல்லாமல் இருப்பின் Power Builder ஐ நிறுவவேண்டிய அவசியம் இல்லை.
ஏதேனும் பிழைகளோ அல்லது புதிய அம்சங்களை உங்களது Inventory Applicationல் சேர்க்கவேண்டிய கட்டாயமோ இருப்பின் PowerBuilder ஐ ஒரு ஓரமாக நிறுவிக்கொள்வார்கள்.
புதிய அம்சங்களை, புதிய மேம்பாடுகளை உங்கள் Applicationல் உருவாக்குவதற்காக Power Builderல் புதிய நிரல்களை எழுதுவார்கள்.
ஏற்கனவே எழுதிய நிரல்களின் தொகுப்புதான் ஒரு Inventory.exe இதை நினைவில் வைக்கவும்.
புதிதாகச் சேர்க்கப்படவேண்டிய புதிய அம்சங்கள், மேம்பாடுகள் (Updates) போன்றவற்றை உருவாக்குவதற்காக PowerBuilder மூலம் ஏற்கனவே உள்ள codingஉடன் புதிதாக coding எழுதி அனைத்தையும் ஒருங்குபடுத்தி (Integrate) மீண்டும் ஒரு புதிய Inventory.exe ஐ உருவாக்குவார்கள். அல்லது புதிய Installation package உருவாக்குவார்கள்.
ஒவ்வொரு முறையும் உங்களது தேவைக்கேற்றபடி Applicationல் மாற்றங்கள் செய்யப்படவேண்டும் என்றால் - ஒவ்வொரு முறையும் புதிது புதிதாக coding எழுதவோ அல்லது ஏற்கனவே எழுதப்பட்ட Coding ல் மாறுதல் செய்யவோதான் Power Builderஐ பயன்படுத்துகிறார்கள். எல்லா மாற்றங்களும் , மேம்பாடுகளும் செய்யப்பட்ட பிறகு கிடைக்கக்கூடிய புதிய EXE ஐ உங்களுக்கு வழங்குவார்கள்.
Oracleக்குப் போட்டியாளர் மென்பொருள்தான் SQL Server.
PowerBuilder க்குப் பதிலாக Visual Basic, C#, VC++ போன்றவற்றைப் பயன்படுத்தி Front End உருவாக்கலாம்.
MS-Access என்பது ஒரு மிகச்சிறிய அளவிலான தகவல்களைக் கையாள்வதற்குப் பயன்படும் Database தான்.
மிகப்பிரமாண்டமான அளவில் இருக்கும் தகவல்களைக் கையாள்வதற்கு Oracle, SQL Server போன்றவற்றைப் பயன்படுத்தலாம்.
MS-Access ஐப் பயன்படுத்தியும் Inventory Applicationஐச் செய்யலாம். ஆனால் அதன் மூலம் மிக அதிக அளவிலான தகவல்களைக் கையாள இயலாது.
Table என்பதை வெறும் Table எனத்தப்புக் கணக்குப் போட்டுவிடவேண்டாம். அனைத்துத் தகவல்களுமே இந்த Tableகளில்தான் Row by Row ஆகப் பதிவாகி இருக்கின்றன என்பதை மறந்துவிடவேண்டாம்.
இத்தனை மில்லியன் தகவல்களில் குறிப்பிட்ட தகவலைத் தேடி எடுக்கவே Query பயன்படுகிறது. இந்த queryகளை எழுத SQL உதவுகிறது.
SQL Server என்பது ஒரு பயன்பாடு. இதன் மூலம் பல Databaseகளை உருவாக்கிக்கொள்ளலாம். ஒவ்வொரு Databaseகளிலும் பல்வேறு Tableகளையும் ஒவ்வொரு Tableலும் ஏராளமான Rows இருக்கும்.
இந்தப் பதிவை முதல்முறை படிக்கும்போது புரியாமல் போவதற்கு வாய்ப்பளிக்கக்கூடாது என்பதற்காகவே குறிப்பிட்ட வரிகளைத் திரும்பத் திரும்ப எழுதியுள்ளேன்.
Friday, February 13, 2009
Thursday, February 12, 2009
எளிய தமிழில் SQL - பாகம் 16
இன்றைய பாகம்-16ல் SQL ன் Aggregate Functions மற்றும், Grouping போன்றவற்றைக் காணலாம்.
இதற்கான ஒரு மாதிரி Table Structure கீழே:
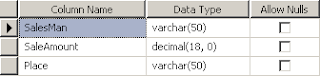
இந்த Table ஐப் பயன்படுத்தி இன்றையப் பாகத்தைத் தொடருவோம்.
Aggregate Functions என்றால் என்ன?
SUM, AVG, MIN, MAX, COUNT போன்றவற்றைப் பயன்படுத்தி கணித விடை காணல். இதன் விடையாக ஒரே ஒரு மதிப்பு மட்டும் வெளியாகும்.
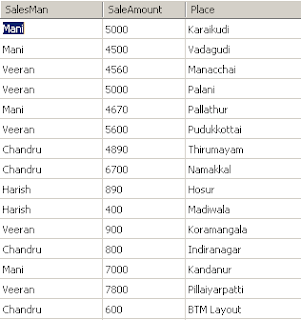
இந்த Tableல் மணி, வீரன், சந்த்ரு, ஹாரிஸ் ஆகிய 3 விற்பனையாளர்களும் வெவ்வேறு காலகட்டங்களில் வேறு வேறு பகுதிகளில் எவ்வளவு தொகைக்கு விற்பனை செய்துள்ளனர் என்பதை அறியக் கொடுத்துள்ளேன்.
அனைவரும் சேர்ந்து ஒட்டுமொத்தமாக எவ்வளவு தொகைக்குப் பொருட்களை விற்பனை செய்துள்ளனர். இதற்கு SUM பயன்படுத்தலாம்.
ஒட்டுமொத்தமான கூடுதல் தொகை.
SELECT SUM(SaleAmount) AS [Total Sale Amount] from Sales
விடை : 59310
அதிகபட்சமாக விற்பனையான தொகை
SELECT MAX(SaleAmount) AS [Maximum] from Sales
விடை : 7800
குறைந்தபட்சமாக விற்பனையான தொகை
SELECT MIN(SaleAmount) AS [Minimum] from Sales
விடை : 400
சராசரித் தொகை
SELECT AVG(SaleAmount) AS [Average] from Sales
விடை : 3954.000000
மொத்தத்தில் எத்தனை முறை விற்பனை நடந்துள்ளது?
SELECT count(*) AS [Total Transactions] from Sales
விடை : 15
மொத்தம் எத்தனை விற்பனையாளர்கள் ?
SELECT COUNT(DISTINCT SalesMan)AS [Total Persons Involved] FROM Sales
விடை:4
இங்கே மாதிரி Tableல் ஒவ்வொரு பிரதிநிதிகளும், ஒன்றுக்கு மேற்பட்டமுறை விற்பனை செய்துள்ளனர். ஆதலால் ஒவ்வொரு பிரதிநிதியின் தனிப்பட்ட கூடுதல், அதிகபட்ச / குறைந்தபட்ச விற்பனைத்தொகை முதலியவற்றைக் காண்பதற்கு GROUP BY பயன்படுத்தலாம்.
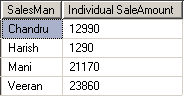
ஒவ்வொருவரின் தனிப்பட்ட விற்பனைத்தொகையைக் காண
SELECT SalesMan,SUM(SaleAmount) as [Individual SaleAmount]
FROM Sales GROUP BY SalesMan
விடை :
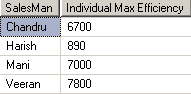
ஒவ்வொருவரின் அதிகபட்ச விற்பனைத்தொகையைக் காண்பதற்கு
SELECT SalesMan,MAX(SaleAmount) as [Individual Max Efficiency]
FROM Sales GROUP BY SalesMan
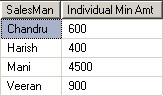
 ஒவ்வொருவரின் குறைந்தபட்ச திறனைக் காண
ஒவ்வொருவரின் குறைந்தபட்ச திறனைக் காண
SELECT SalesMan,MIN(SaleAmount) as [Individual Min Amt] FROM Sales GROUP BY SalesMan
SELECT உடன் மேலும் அதிகமான கட்டுப்பாடுகளை விதிப்பதற்கும் Conditionகளைக் கூறுவதற்கும் WHERE சேர்த்துப் பயன்படுத்துவோம். அதுபோல இங்கே Aggregate Functions பயன்படுத்தும்போது HAVING ஐ இணைத்துப் பயன்படுத்துவோம்.
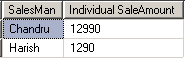
விற்பனைப் பிரதிநிதிகளின் இரண்டாவது எழுத்து 'a' ஆக உள்ளவர்களையும், அவர்களது ஒட்டுமொத்த விற்றதொகையையும் காண
SELECT SalesMan,SUM(SaleAmount) as [Individual SaleAmount]
FROM Sales GROUP BY SalesMan
HAVING SalesMan LIKE '_a%'
 _ மற்றும் % ஆகிய அடையாளங்களுக்கு Wild card characters என்று பெயர். அதாவது இட நிரப்பிகள். _ என்பது ஒரு எழுத்தை மட்டும் நிரப்பும். % என்பது அனைத்து எழுத்துகளையும் நிரப்பும்.
_ மற்றும் % ஆகிய அடையாளங்களுக்கு Wild card characters என்று பெயர். அதாவது இட நிரப்பிகள். _ என்பது ஒரு எழுத்தை மட்டும் நிரப்பும். % என்பது அனைத்து எழுத்துகளையும் நிரப்பும்.
‘_a%' என்றால் முதல் எழுத்து ஏதோ ஒன்றாகவும், கண்டிப்பாக இரண்டாம் எழுத்து 'a' பிற எழுத்துகளைப் பற்றிக் கவலையில்லை. இப்படி எந்த பிரதிநிதியின் பெயரில் இரண்டாவது எழுத்து 'a' வருகிறதோ அவர்களை மட்டும் காண்பதற்கு.
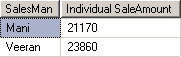
ஒட்டுமொத்தத்தில் 20000 ஐ விட அதிகமாக விற்பனை செய்தவர்களை மட்டும் காண்பதற்கு:
SELECT SalesMan, SUM(SaleAmount) as [Individual SaleAmount] FROM Sales
GROUP BY SalesMan
HAVING SUM(SaleAmount) > 20000
 மொத்தவிற்பனை 5000 ரூபாயைவிடக் குறைவாக விற்றவர் யார்?
மொத்தவிற்பனை 5000 ரூபாயைவிடக் குறைவாக விற்றவர் யார்?
SELECT SalesMan,SUM(SaleAmount) as [Individual SaleAmount] FROM Sales
GROUP BY SalesMan
HAVING SUM(SaleAmount)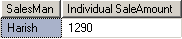 5000 ரூபாய்கள் முதல் 20000 ரூபாய்கள் வரை விற்பனை செய்தோர் யாவர்?
5000 ரூபாய்கள் முதல் 20000 ரூபாய்கள் வரை விற்பனை செய்தோர் யாவர்?
SELECT SalesMan,SUM(SaleAmount) as [Individual SaleAmount] FROM Sales
GROUP BY SalesMan
HAVING SUM(SaleAmount) BETWEEN 1000 AND 20000
கீழே உள்ளதைக் கவனிக்கவும்.
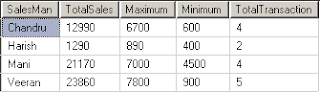
SELECT SalesMan, SUM(SaleAmount) as [TotalSales], MAX(SaleAmount) as [Maximum], Min(SaleAmount) as [Minimum], count(SaleAmount)as [TotalTransaction] from Sales
நான் எதையோ எதிர்பார்த்து இப்படிக் கொடுத்தால் என்ன ஆகும். Sum, Max, Min, Count அனைத்தையும் கொடுத்துள்ளேன். ஆனால் GROUP BY மட்டும் கொடுக்காமல் விட்டுவிட்டேன். இப்போது என்ன ஆகும்?
கீழேயுள்ள பிழைச்செய்திதான் கிடைக்கும். குழுவாகப் பிரித்து ஒவ்வொருவரின் தனித்திறமையைக் காண்பதற்கே GROUP BY பயன்படுகிறது.
Msg 8120, Level 16, State 1, Line 1
Column 'Sales.SalesMan' is invalid in the select list because it is not contained in either an aggregate function or the GROUP BY clause.
இதைச் சரிசெய்த பிறகு,
SELECT SalesMan, SUM(SaleAmount) as [TotalSales], MAX(SaleAmount) as [Maximum], Min(SaleAmount) as [Minimum], count(SaleAmount)as [TotalTransaction]
from Sales
GROUP BY SalesMan
இதன் விடை:
இதற்கான ஒரு மாதிரி Table Structure கீழே:

இந்த Table ஐப் பயன்படுத்தி இன்றையப் பாகத்தைத் தொடருவோம்.
Aggregate Functions என்றால் என்ன?
SUM, AVG, MIN, MAX, COUNT போன்றவற்றைப் பயன்படுத்தி கணித விடை காணல். இதன் விடையாக ஒரே ஒரு மதிப்பு மட்டும் வெளியாகும்.

இந்த Tableல் மணி, வீரன், சந்த்ரு, ஹாரிஸ் ஆகிய 3 விற்பனையாளர்களும் வெவ்வேறு காலகட்டங்களில் வேறு வேறு பகுதிகளில் எவ்வளவு தொகைக்கு விற்பனை செய்துள்ளனர் என்பதை அறியக் கொடுத்துள்ளேன்.
அனைவரும் சேர்ந்து ஒட்டுமொத்தமாக எவ்வளவு தொகைக்குப் பொருட்களை விற்பனை செய்துள்ளனர். இதற்கு SUM பயன்படுத்தலாம்.
ஒட்டுமொத்தமான கூடுதல் தொகை.
SELECT SUM(SaleAmount) AS [Total Sale Amount] from Sales
விடை : 59310
அதிகபட்சமாக விற்பனையான தொகை
SELECT MAX(SaleAmount) AS [Maximum] from Sales
விடை : 7800
குறைந்தபட்சமாக விற்பனையான தொகை
SELECT MIN(SaleAmount) AS [Minimum] from Sales
விடை : 400
சராசரித் தொகை
SELECT AVG(SaleAmount) AS [Average] from Sales
விடை : 3954.000000
மொத்தத்தில் எத்தனை முறை விற்பனை நடந்துள்ளது?
SELECT count(*) AS [Total Transactions] from Sales
விடை : 15
மொத்தம் எத்தனை விற்பனையாளர்கள் ?
SELECT COUNT(DISTINCT SalesMan)AS [Total Persons Involved] FROM Sales
விடை:4
இங்கே மாதிரி Tableல் ஒவ்வொரு பிரதிநிதிகளும், ஒன்றுக்கு மேற்பட்டமுறை விற்பனை செய்துள்ளனர். ஆதலால் ஒவ்வொரு பிரதிநிதியின் தனிப்பட்ட கூடுதல், அதிகபட்ச / குறைந்தபட்ச விற்பனைத்தொகை முதலியவற்றைக் காண்பதற்கு GROUP BY பயன்படுத்தலாம்.
ஒவ்வொருவரின் தனிப்பட்ட விற்பனைத்தொகையைக் காண
SELECT SalesMan,SUM(SaleAmount) as [Individual SaleAmount]
FROM Sales GROUP BY SalesMan
விடை :

ஒவ்வொருவரின் அதிகபட்ச விற்பனைத்தொகையைக் காண்பதற்கு
SELECT SalesMan,MAX(SaleAmount) as [Individual Max Efficiency]
FROM Sales GROUP BY SalesMan
 ஒவ்வொருவரின் குறைந்தபட்ச திறனைக் காண
ஒவ்வொருவரின் குறைந்தபட்ச திறனைக் காணSELECT SalesMan,MIN(SaleAmount) as [Individual Min Amt] FROM Sales GROUP BY SalesMan

SELECT உடன் மேலும் அதிகமான கட்டுப்பாடுகளை விதிப்பதற்கும் Conditionகளைக் கூறுவதற்கும் WHERE சேர்த்துப் பயன்படுத்துவோம். அதுபோல இங்கே Aggregate Functions பயன்படுத்தும்போது HAVING ஐ இணைத்துப் பயன்படுத்துவோம்.
விற்பனைப் பிரதிநிதிகளின் இரண்டாவது எழுத்து 'a' ஆக உள்ளவர்களையும், அவர்களது ஒட்டுமொத்த விற்றதொகையையும் காண
SELECT SalesMan,SUM(SaleAmount) as [Individual SaleAmount]
FROM Sales GROUP BY SalesMan
HAVING SalesMan LIKE '_a%'
 _ மற்றும் % ஆகிய அடையாளங்களுக்கு Wild card characters என்று பெயர். அதாவது இட நிரப்பிகள். _ என்பது ஒரு எழுத்தை மட்டும் நிரப்பும். % என்பது அனைத்து எழுத்துகளையும் நிரப்பும்.
_ மற்றும் % ஆகிய அடையாளங்களுக்கு Wild card characters என்று பெயர். அதாவது இட நிரப்பிகள். _ என்பது ஒரு எழுத்தை மட்டும் நிரப்பும். % என்பது அனைத்து எழுத்துகளையும் நிரப்பும்.‘_a%' என்றால் முதல் எழுத்து ஏதோ ஒன்றாகவும், கண்டிப்பாக இரண்டாம் எழுத்து 'a' பிற எழுத்துகளைப் பற்றிக் கவலையில்லை. இப்படி எந்த பிரதிநிதியின் பெயரில் இரண்டாவது எழுத்து 'a' வருகிறதோ அவர்களை மட்டும் காண்பதற்கு.
ஒட்டுமொத்தத்தில் 20000 ஐ விட அதிகமாக விற்பனை செய்தவர்களை மட்டும் காண்பதற்கு:
SELECT SalesMan, SUM(SaleAmount) as [Individual SaleAmount] FROM Sales
GROUP BY SalesMan
HAVING SUM(SaleAmount) > 20000
 மொத்தவிற்பனை 5000 ரூபாயைவிடக் குறைவாக விற்றவர் யார்?
மொத்தவிற்பனை 5000 ரூபாயைவிடக் குறைவாக விற்றவர் யார்?SELECT SalesMan,SUM(SaleAmount) as [Individual SaleAmount] FROM Sales
GROUP BY SalesMan
HAVING SUM(SaleAmount)
 5000 ரூபாய்கள் முதல் 20000 ரூபாய்கள் வரை விற்பனை செய்தோர் யாவர்?
5000 ரூபாய்கள் முதல் 20000 ரூபாய்கள் வரை விற்பனை செய்தோர் யாவர்?SELECT SalesMan,SUM(SaleAmount) as [Individual SaleAmount] FROM Sales
GROUP BY SalesMan
HAVING SUM(SaleAmount) BETWEEN 1000 AND 20000

கீழே உள்ளதைக் கவனிக்கவும்.
SELECT SalesMan, SUM(SaleAmount) as [TotalSales], MAX(SaleAmount) as [Maximum], Min(SaleAmount) as [Minimum], count(SaleAmount)as [TotalTransaction] from Sales
நான் எதையோ எதிர்பார்த்து இப்படிக் கொடுத்தால் என்ன ஆகும். Sum, Max, Min, Count அனைத்தையும் கொடுத்துள்ளேன். ஆனால் GROUP BY மட்டும் கொடுக்காமல் விட்டுவிட்டேன். இப்போது என்ன ஆகும்?
கீழேயுள்ள பிழைச்செய்திதான் கிடைக்கும். குழுவாகப் பிரித்து ஒவ்வொருவரின் தனித்திறமையைக் காண்பதற்கே GROUP BY பயன்படுகிறது.
Msg 8120, Level 16, State 1, Line 1
Column 'Sales.SalesMan' is invalid in the select list because it is not contained in either an aggregate function or the GROUP BY clause.
இதைச் சரிசெய்த பிறகு,
SELECT SalesMan, SUM(SaleAmount) as [TotalSales], MAX(SaleAmount) as [Maximum], Min(SaleAmount) as [Minimum], count(SaleAmount)as [TotalTransaction]
from Sales
GROUP BY SalesMan
இதன் விடை:

Tuesday, February 10, 2009
எளிய தமிழில் SQL - பாகம் 15
இன்றைய பாகம் 15ல் இரண்டு tableகளை இணைப்பது குறித்து இன்னும் விவரமாகப் பார்க்க இருக்கிறோம்.
பாகம் 14ல் Primarykey மற்றும் Foreign key ஆகியவற்றைப் பயன்படுத்துவது என்பது குறித்துப் பார்த்தோம். அதன் தொடர்ச்சியாக இதைக் கொண்டாலும் இதில் சில விதிவிலக்குகள் புரிதலுக்காகச் செய்திருக்கிறேன்.
ஒன்றுக்கு மேற்பட்ட Tableகளை இணைத்து அனைத்து அறிக்கைகளையும் ஒரே திரையில் காண்பதற்கு JOIN பயன்படுத்தப்படுகிறது.
JOINன் வகைகள்
INNER JOIN
OUTER JOIN
SELF JOIN
CROSS JOIN
OUTER JOIN ஐ இன்னும் 3 வகை உட்பிரிவுகளாகப் பிரித்து, LEFT OUTER, RIGHT OUTER, FULL OUTER எனப் பிரிக்கலாம்.
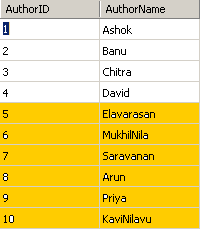
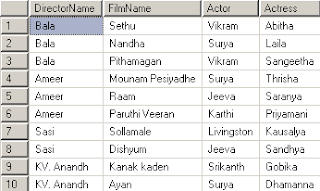
இங்கே மாதிரிக்காக 2 tableகளை உருவாக்கி அவற்றில் சில மாதிரி records ஐ ஏற்றியிருக்கிறேன். அவற்றின் பெயர்கள் Author மற்றும் Publication ஆகியவை.
Author அட்டவணையின் Structure மற்றும் மாதிரி தகவல்கள் ஆகியவை கீழே:

 Publication அட்டவணையின் Structure Structure மற்றும் மாதிரி தகவல்கள் ஆகியவை கீழே:
Publication அட்டவணையின் Structure Structure மற்றும் மாதிரி தகவல்கள் ஆகியவை கீழே:

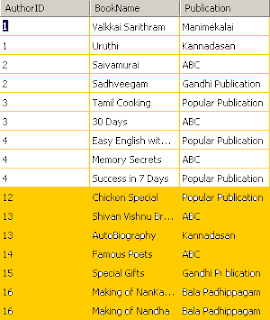
எழுத்தாளர் அட்டவணையில் உள்ள முதல் 4 Authorகள் பதிப்பக அட்டவணையில் வேறுவேறு நூல்களை எழுதி இருக்கின்றனர். ஆனால் மீதமுள்ள 6 எழுத்தாளர்கள் எழுதிய நூல்களின் விவரங்கள் பதிப்பக அட்டவணையில் இல்லை.
அதேபோல பதிப்பக அட்டவணையில் உள்ள குறிப்பிட்ட Chicken Special முதல் Making of Nandha வரையிலான புத்தகங்களின் எழுத்தாளர்கள் பற்றிய விவரங்கள் Author அட்டவணையில் இல்லை. இது ஒரு மாதிரிக்காக உருவாக்கப்பட்ட tableகள். இவற்றின் மூலம் நாம் tableகளை இணைக்கும் JOIN பற்றி எளிதாக அறிந்துகொள்ளலாம்.
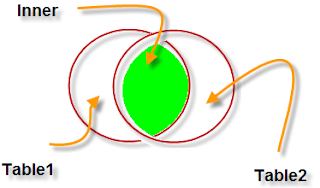
முதலில் INNER JOIN பற்றிப் பார்ப்போம். அதன் Syntax கீழே:
SELECT table1.Field1, table1.Field2, table2.Field1, table2.Field2
FROM
table1 INNER JOIN table2
ON
table1.CommonField = table2.CommonField
இங்கே table1 = Author , table2 = Publication என அறிக.
இதற்கான உதாரணத்தைக் கவனிக்கவும்
SELECT Author.AuthorID, Author.AuthorName, Publication.BookName
FROM Author INNER JOIN
Publication ON Author.AuthorID = Publication.AuthorID
இதன் விடை:
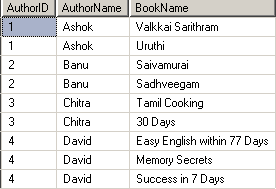
இங்கே இரண்டு tableகளுக்கும் பொதுவாக அமைந்துள்ள rows மட்டுமே இடம்பெற்றுள்ளன.
Author அட்டவணையிலும், Publication அட்டவணையிலும் வண்ணமிட்டுக் காட்டப்பட்ட தகவல்களைக் காணவில்லை. பொதுவாக உள்ளவை மட்டுமே இடம்பெற்றுள்ளன. கீழேயுள்ள கணம் பற்றிய படத்தைக் கவனிக்கவும்.
LEFT OUTER JOIN பற்றிப் பார்ப்போம். அதன் Syntax கீழே:
SELECT table1.Field1, table1.Field2, table2.Field1, table2.Field2
FROM
table1 LEFT OUTER JOIN table2
ON
table1.CommonField = table2.CommonField
இங்கே table1 = Author , table2 = Publication என அறிக.
இதற்கான உதாரணத்தைக் கவனிக்கவும்
SELECT Author.AuthorID, Author.AuthorName, Publication.BookName
FROM Author LEFT OUTER JOIN
Publication ON Author.AuthorID = Publication.AuthorID
இதன் விடை:
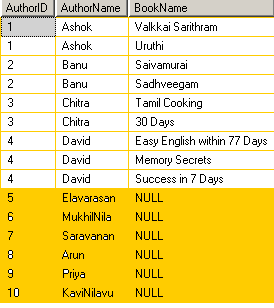 இங்கே முதலாவது table ஆகிய Author ல் இருக்கும் அனைத்து rowsஇடம் பெற்றுள்ளன. ஒரே எழுத்தாளர் ஒன்றுக்கு மேற்பட்ட புத்தகங்களை எழுதியுள்ளதால் அவர்கள் திரும்பத்திரும்ப இடம்பெற்றிருக்கிறார்கள்.
இங்கே முதலாவது table ஆகிய Author ல் இருக்கும் அனைத்து rowsஇடம் பெற்றுள்ளன. ஒரே எழுத்தாளர் ஒன்றுக்கு மேற்பட்ட புத்தகங்களை எழுதியுள்ளதால் அவர்கள் திரும்பத்திரும்ப இடம்பெற்றிருக்கிறார்கள்.
5 முதல் 10 வரையிலான எழுத்தாளர்கள் எழுதிய புத்தகங்கள் Publication அட்டவணையில் இல்லாததால் அவர்களுக்கு நேரே உள்ள BookName ல் NULL மூலம் நிரப்பப்பட்டுவிட்டது.
இடதுபுற (Left side = Author) அட்டவணையில் எல்லா recordsம் தேர்வுசெய்யப்பட்டுவிடும். ஆனால் வலது புறத்தில் உறவுமுறை (Relation) இல்லாத rows எல்லாவற்றிலும் NULL நிரப்பப்பட்டுக் காண்பிக்கப்படும்.
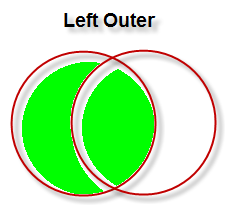
மேலே காட்டப்பட்டிருக்கு கணம் பற்றிய படத்தைக் கவனிக்கவும்.
RIGHT OUTER JOIN பற்றிப் பார்ப்போம். அதன் Syntax கீழே:
SELECT table1.Field1, table1.Field2, table2.Field1, table2.Field2,table2.Field3
FROM
table1 RIGHT OUTER JOIN table2
ON
table1.CommonField = table2.CommonField
இங்கே table1 = Author , table2 = Publication என அறிக.
இதற்கான உதாரணத்தைக் கவனிக்கவும்
SELECT Author.AuthorID, Author.AuthorName, Publication.BookName,Publication.Publication
FROM Author RIGHT OUTER JOIN
Publication ON Author.AuthorID = Publication.AuthorID
இதன் விடை: AuthorIDல் 5 முதல் 10 வரையிலான அனைத்து Authorகளைத் தவிர மீதியுள்ளோர் மட்டுமே இடதுபுறம் இடம்பெற்றுள்ளனர். Chicken Special முதல் Making of Nandha வரையிலான நூல்களை எழுதிய Author பற்றிய குறிப்புகள் Author அட்டவணையில் இல்லை - அதனால் அவற்றுக்கு நேராக NULL நிரப்பப்பட்டுவிட்டது. Right Outer Join ல் வலது புறம் (Right side) உள்ள அட்டவணையின் அனைத்து records ம் திரையில் காண்பிக்கப்படும். ஒப்புமை இல்லாத இடதுபுற rowsக்கு மட்டும் NULL நிரப்பப்பட்டுவிடும்.
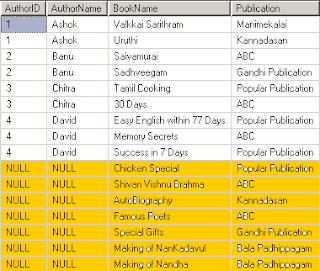 கீழேயுள்ள கணம் பற்றிய படத்தைக் கவனிக்கவும்.
கீழேயுள்ள கணம் பற்றிய படத்தைக் கவனிக்கவும்.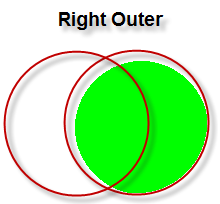 இப்போது FULL OUTER பற்றிப் பார்ப்போம்.
இப்போது FULL OUTER பற்றிப் பார்ப்போம்.
அதன் Syntax கீழே:
SELECT table1.Field1, table1.Field2, table2.Field1, table2.Field2,table2.Field3
FROM
table1 FULL OUTER JOIN table2
ON
table1.CommonField = table2.CommonField
இங்கே table1 = Author , table2 = Publication என அறிக.
இதற்கான உதாரணத்தைக் கவனிக்கவும்
SELECT Author.AuthorID, Author.AuthorName, Publication.BookName,Publication.Publication
FROM Author FULL OUTER JOIN
Publication ON Author.AuthorID = Publication.AuthorID
இதன் விடை:
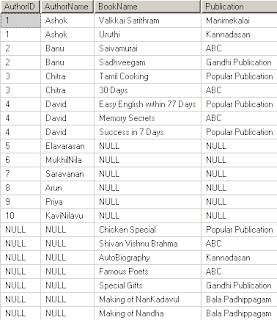
இரண்டுபுறமுள்ள tableகளிலும் உள்ள பொதுவான rows அதன் இடங்களில் சரியாக இடம்பெற்றுள்ளன. உறவுமுறையில்லாத recordsம் இடம்பெற்றுள்ளன. ஆனால் எங்கெங்கு தகவல்கள் இல்லையோ அங்கேயெல்லாம் NULL மூலம் நிரப்பப்பட்டுவிட்டன. Author அட்டவணையின் Elavarasan முதல் KaviNilavu வரையிலான எழுத்தாளர்களும் இடம்பெற்றிருக்கின்றனர். ஆனால் அவர்கள் எழுதிய புத்தகங்கள் Publication அட்டவணையில் இல்லாத காரணத்தால் வலதுபுறத்தில் NULL இடம்பெற்றுள்ளது. அதேபோல Chicken Special முதல் Making of Nandha வரையிலான நூல்களை எழுதியவர்களின் விபரம் Author அட்டவணையில் இல்லாததால் இடப்பக்கமாக NULL நிரப்பப்பட்டுவிட்டது.
CROSS JOIN பற்றிப் பார்ப்போம்.
Cross join என்பது குறுக்குப் பெருக்கல் ஆகும்.
இதன் மாதிரி வடிவம்:
SELECT Author.AuthorName, Publication.BookName, Publication.Publication
FROM Author CROSS JOIN
Publication
மொத்த rowsன் எண்ணிக்கை = இடப்புறம் உள்ள rowsகளின் எண்ணிக்க x வலப்புறம் உள்ள rows எண்ணிக்கை.
SELECT COUNT(*) FROM Author --> 10 records உள்ளன
SELECT COUNT(*) FROM Publication --> 16 rows உள்ளன.
Count(*) இந்த Function மூலம் ஒரு tableல் எத்தனை rows உள்ளன என அறியலாம்.
Cross join இணைப்பிற்குப் பிறகு உருவாகும்
rowsகளின் எண்ணிக்கை = 10 x 16 = 160.
இடப்புறமுள்ள ஒவ்வொரு recordம் , வலப்புறமுள்ள அனைத்து recordsஉடன் ஒவ்வொருமுறையும் இணைத்துக் காட்சியளிக்கும்.
SELF JOIN என்பது ஒரே table ஆனது, அதற்குள்ளேயே இணைக்கப்படுவதால் அவ்வாறு அழைக்கப்படுகிறது.
பாகம் 14ல் Primarykey மற்றும் Foreign key ஆகியவற்றைப் பயன்படுத்துவது என்பது குறித்துப் பார்த்தோம். அதன் தொடர்ச்சியாக இதைக் கொண்டாலும் இதில் சில விதிவிலக்குகள் புரிதலுக்காகச் செய்திருக்கிறேன்.
ஒன்றுக்கு மேற்பட்ட Tableகளை இணைத்து அனைத்து அறிக்கைகளையும் ஒரே திரையில் காண்பதற்கு JOIN பயன்படுத்தப்படுகிறது.
JOINன் வகைகள்
INNER JOIN
OUTER JOIN
SELF JOIN
CROSS JOIN
OUTER JOIN ஐ இன்னும் 3 வகை உட்பிரிவுகளாகப் பிரித்து, LEFT OUTER, RIGHT OUTER, FULL OUTER எனப் பிரிக்கலாம்.
இங்கே மாதிரிக்காக 2 tableகளை உருவாக்கி அவற்றில் சில மாதிரி records ஐ ஏற்றியிருக்கிறேன். அவற்றின் பெயர்கள் Author மற்றும் Publication ஆகியவை.
Author அட்டவணையின் Structure மற்றும் மாதிரி தகவல்கள் ஆகியவை கீழே:

 Publication அட்டவணையின் Structure Structure மற்றும் மாதிரி தகவல்கள் ஆகியவை கீழே:
Publication அட்டவணையின் Structure Structure மற்றும் மாதிரி தகவல்கள் ஆகியவை கீழே:

எழுத்தாளர் அட்டவணையில் உள்ள முதல் 4 Authorகள் பதிப்பக அட்டவணையில் வேறுவேறு நூல்களை எழுதி இருக்கின்றனர். ஆனால் மீதமுள்ள 6 எழுத்தாளர்கள் எழுதிய நூல்களின் விவரங்கள் பதிப்பக அட்டவணையில் இல்லை.
அதேபோல பதிப்பக அட்டவணையில் உள்ள குறிப்பிட்ட Chicken Special முதல் Making of Nandha வரையிலான புத்தகங்களின் எழுத்தாளர்கள் பற்றிய விவரங்கள் Author அட்டவணையில் இல்லை. இது ஒரு மாதிரிக்காக உருவாக்கப்பட்ட tableகள். இவற்றின் மூலம் நாம் tableகளை இணைக்கும் JOIN பற்றி எளிதாக அறிந்துகொள்ளலாம்.
முதலில் INNER JOIN பற்றிப் பார்ப்போம். அதன் Syntax கீழே:
SELECT table1.Field1, table1.Field2, table2.Field1, table2.Field2
FROM
table1 INNER JOIN table2
ON
table1.CommonField = table2.CommonField
இங்கே table1 = Author , table2 = Publication என அறிக.
இதற்கான உதாரணத்தைக் கவனிக்கவும்
SELECT Author.AuthorID, Author.AuthorName, Publication.BookName
FROM Author INNER JOIN
Publication ON Author.AuthorID = Publication.AuthorID
இதன் விடை:

இங்கே இரண்டு tableகளுக்கும் பொதுவாக அமைந்துள்ள rows மட்டுமே இடம்பெற்றுள்ளன.
Author அட்டவணையிலும், Publication அட்டவணையிலும் வண்ணமிட்டுக் காட்டப்பட்ட தகவல்களைக் காணவில்லை. பொதுவாக உள்ளவை மட்டுமே இடம்பெற்றுள்ளன. கீழேயுள்ள கணம் பற்றிய படத்தைக் கவனிக்கவும்.

LEFT OUTER JOIN பற்றிப் பார்ப்போம். அதன் Syntax கீழே:
SELECT table1.Field1, table1.Field2, table2.Field1, table2.Field2
FROM
table1 LEFT OUTER JOIN table2
ON
table1.CommonField = table2.CommonField
இங்கே table1 = Author , table2 = Publication என அறிக.
இதற்கான உதாரணத்தைக் கவனிக்கவும்
SELECT Author.AuthorID, Author.AuthorName, Publication.BookName
FROM Author LEFT OUTER JOIN
Publication ON Author.AuthorID = Publication.AuthorID
இதன் விடை:
 இங்கே முதலாவது table ஆகிய Author ல் இருக்கும் அனைத்து rowsஇடம் பெற்றுள்ளன. ஒரே எழுத்தாளர் ஒன்றுக்கு மேற்பட்ட புத்தகங்களை எழுதியுள்ளதால் அவர்கள் திரும்பத்திரும்ப இடம்பெற்றிருக்கிறார்கள்.
இங்கே முதலாவது table ஆகிய Author ல் இருக்கும் அனைத்து rowsஇடம் பெற்றுள்ளன. ஒரே எழுத்தாளர் ஒன்றுக்கு மேற்பட்ட புத்தகங்களை எழுதியுள்ளதால் அவர்கள் திரும்பத்திரும்ப இடம்பெற்றிருக்கிறார்கள்.5 முதல் 10 வரையிலான எழுத்தாளர்கள் எழுதிய புத்தகங்கள் Publication அட்டவணையில் இல்லாததால் அவர்களுக்கு நேரே உள்ள BookName ல் NULL மூலம் நிரப்பப்பட்டுவிட்டது.
இடதுபுற (Left side = Author) அட்டவணையில் எல்லா recordsம் தேர்வுசெய்யப்பட்டுவிடும். ஆனால் வலது புறத்தில் உறவுமுறை (Relation) இல்லாத rows எல்லாவற்றிலும் NULL நிரப்பப்பட்டுக் காண்பிக்கப்படும்.

மேலே காட்டப்பட்டிருக்கு கணம் பற்றிய படத்தைக் கவனிக்கவும்.
RIGHT OUTER JOIN பற்றிப் பார்ப்போம். அதன் Syntax கீழே:
SELECT table1.Field1, table1.Field2, table2.Field1, table2.Field2,table2.Field3
FROM
table1 RIGHT OUTER JOIN table2
ON
table1.CommonField = table2.CommonField
இங்கே table1 = Author , table2 = Publication என அறிக.
இதற்கான உதாரணத்தைக் கவனிக்கவும்
SELECT Author.AuthorID, Author.AuthorName, Publication.BookName,Publication.Publication
FROM Author RIGHT OUTER JOIN
Publication ON Author.AuthorID = Publication.AuthorID
இதன் விடை: AuthorIDல் 5 முதல் 10 வரையிலான அனைத்து Authorகளைத் தவிர மீதியுள்ளோர் மட்டுமே இடதுபுறம் இடம்பெற்றுள்ளனர். Chicken Special முதல் Making of Nandha வரையிலான நூல்களை எழுதிய Author பற்றிய குறிப்புகள் Author அட்டவணையில் இல்லை - அதனால் அவற்றுக்கு நேராக NULL நிரப்பப்பட்டுவிட்டது. Right Outer Join ல் வலது புறம் (Right side) உள்ள அட்டவணையின் அனைத்து records ம் திரையில் காண்பிக்கப்படும். ஒப்புமை இல்லாத இடதுபுற rowsக்கு மட்டும் NULL நிரப்பப்பட்டுவிடும்.
 கீழேயுள்ள கணம் பற்றிய படத்தைக் கவனிக்கவும்.
கீழேயுள்ள கணம் பற்றிய படத்தைக் கவனிக்கவும். இப்போது FULL OUTER பற்றிப் பார்ப்போம்.
இப்போது FULL OUTER பற்றிப் பார்ப்போம்.அதன் Syntax கீழே:
SELECT table1.Field1, table1.Field2, table2.Field1, table2.Field2,table2.Field3
FROM
table1 FULL OUTER JOIN table2
ON
table1.CommonField = table2.CommonField
இங்கே table1 = Author , table2 = Publication என அறிக.
இதற்கான உதாரணத்தைக் கவனிக்கவும்
SELECT Author.AuthorID, Author.AuthorName, Publication.BookName,Publication.Publication
FROM Author FULL OUTER JOIN
Publication ON Author.AuthorID = Publication.AuthorID
இதன் விடை:

இரண்டுபுறமுள்ள tableகளிலும் உள்ள பொதுவான rows அதன் இடங்களில் சரியாக இடம்பெற்றுள்ளன. உறவுமுறையில்லாத recordsம் இடம்பெற்றுள்ளன. ஆனால் எங்கெங்கு தகவல்கள் இல்லையோ அங்கேயெல்லாம் NULL மூலம் நிரப்பப்பட்டுவிட்டன. Author அட்டவணையின் Elavarasan முதல் KaviNilavu வரையிலான எழுத்தாளர்களும் இடம்பெற்றிருக்கின்றனர். ஆனால் அவர்கள் எழுதிய புத்தகங்கள் Publication அட்டவணையில் இல்லாத காரணத்தால் வலதுபுறத்தில் NULL இடம்பெற்றுள்ளது. அதேபோல Chicken Special முதல் Making of Nandha வரையிலான நூல்களை எழுதியவர்களின் விபரம் Author அட்டவணையில் இல்லாததால் இடப்பக்கமாக NULL நிரப்பப்பட்டுவிட்டது.
CROSS JOIN பற்றிப் பார்ப்போம்.
Cross join என்பது குறுக்குப் பெருக்கல் ஆகும்.
இதன் மாதிரி வடிவம்:
SELECT Author.AuthorName, Publication.BookName, Publication.Publication
FROM Author CROSS JOIN
Publication
மொத்த rowsன் எண்ணிக்கை = இடப்புறம் உள்ள rowsகளின் எண்ணிக்க x வலப்புறம் உள்ள rows எண்ணிக்கை.
SELECT COUNT(*) FROM Author --> 10 records உள்ளன
SELECT COUNT(*) FROM Publication --> 16 rows உள்ளன.
Count(*) இந்த Function மூலம் ஒரு tableல் எத்தனை rows உள்ளன என அறியலாம்.
Cross join இணைப்பிற்குப் பிறகு உருவாகும்
rowsகளின் எண்ணிக்கை = 10 x 16 = 160.
இடப்புறமுள்ள ஒவ்வொரு recordம் , வலப்புறமுள்ள அனைத்து recordsஉடன் ஒவ்வொருமுறையும் இணைத்துக் காட்சியளிக்கும்.
SELF JOIN என்பது ஒரே table ஆனது, அதற்குள்ளேயே இணைக்கப்படுவதால் அவ்வாறு அழைக்கப்படுகிறது.
Thursday, February 5, 2009
எளிய தமிழில் SQL - பாகம் 14
SQL Server பயன்பாட்டை எவ்வாறு நிறுவுவது என திரு. G. ராஜாராமன் சவுதி அரேபியா கேட்டிருந்தார். அவருக்காக இணையத்தில் தேடியபோது ஒரு அருமையான தளமுகவரி கிடைத்தது அதை இங்கே பகிர்கிறேன்.
ஒவ்வொரு திரையாகப் படம் பிடித்து அருமையாக விளக்கியிருக்கிறார்கள்.
http://www.functionx.com/sqlserver/Lesson01.htm
அவர் கேட்டதற்கு இணங்கி அப்படி ஒரு பதிவைத் தமிழில் வெளியிட நினைத்தேன். அழகான செயல்முறை விளக்கத்துடன் ஆங்கிலத்தில் இருந்தாலும் எளிதாகப் புரியும் வண்ணம் இருந்ததால் அதன் சுட்டியை இங்கே பகிர்ந்துவிட்டேன்.
மேலும் SQL க்கான Syntax அட்டவணையை http://www.w3schools.com/sql/sql_quickref.asp ல் கண்டேன். அதனைக் கீழே தந்திருக்கிறேன்.
நன்றி : http://www.w3schools.com
இந்த SQL Syntaxகளை நன்றாகப் படித்து மனதில் வைத்துக்கொள்ளவும்.
Select Statement
SELECT "column_name" FROM "table_name"
Distinct
SELECT DISTINCT "column_name"
FROM "table_name"
Where
SELECT "column_name"
FROM "table_name"
WHERE "condition"
And/Or
SELECT "column_name"
FROM "table_name"
WHERE "simple condition"
{[AND|OR] "simple condition"}+
In
SELECT "column_name"
FROM "table_name"
WHERE "column_name" IN ('value1', 'value2', ...)
Between
SELECT "column_name"
FROM "table_name"
WHERE "column_name" BETWEEN 'value1' AND 'value2'
Like
SELECT "column_name"
FROM "table_name"
WHERE "column_name" LIKE {PATTERN}
Order By
SELECT "column_name"
FROM "table_name"
[WHERE "condition"]
ORDER BY "column_name" [ASC, DESC]
Count
SELECT COUNT("column_name")
FROM "table_name"
Group By
SELECT "column_name1", SUM("column_name2")
FROM "table_name"
GROUP BY "column_name1"
Having
SELECT "column_name1", SUM("column_name2")
FROM "table_name"
GROUP BY "column_name1"
HAVING (arithematic function condition)
Create Table Statement
CREATE TABLE "table_name"
("column 1" "data_type_for_column_1",
"column 2" "data_type_for_column_2",
... )
Drop Table Statement
DROP TABLE "table_name"
Truncate Table Statement
TRUNCATE TABLE "table_name"
Insert Into Statement
INSERT INTO "table_name" ("column1", "column2", ...)
VALUES ("value1", "value2", ...)
Update Statement
UPDATE "table_name"
SET "column_1" = [new value]
WHERE {condition}
Delete From Statement
DELETE FROM "table_name"
WHERE {condition}
ஒவ்வொரு திரையாகப் படம் பிடித்து அருமையாக விளக்கியிருக்கிறார்கள்.
http://www.functionx.com/sqlserver/Lesson01.htm
அவர் கேட்டதற்கு இணங்கி அப்படி ஒரு பதிவைத் தமிழில் வெளியிட நினைத்தேன். அழகான செயல்முறை விளக்கத்துடன் ஆங்கிலத்தில் இருந்தாலும் எளிதாகப் புரியும் வண்ணம் இருந்ததால் அதன் சுட்டியை இங்கே பகிர்ந்துவிட்டேன்.
மேலும் SQL க்கான Syntax அட்டவணையை http://www.w3schools.com/sql/sql_quickref.asp ல் கண்டேன். அதனைக் கீழே தந்திருக்கிறேன்.
நன்றி : http://www.w3schools.com
இந்த SQL Syntaxகளை நன்றாகப் படித்து மனதில் வைத்துக்கொள்ளவும்.
| AND / OR | SELECT column_name(s) FROM table_name WHERE condition AND|OR condition |
| ALTER TABLE | ALTER TABLE table_name ADD column_name datatype or ALTER TABLE table_name |
| AS (alias) | SELECT column_name AS column_alias FROM table_name or SELECT column_name |
| BETWEEN | SELECT column_name(s) FROM table_name WHERE column_name BETWEEN value1 AND value2 |
| CREATE DATABASE | CREATE DATABASE database_name |
| CREATE TABLE | CREATE TABLE table_name ( column_name1 data_type, column_name2 data_type, column_name2 data_type, ... ) |
| CREATE INDEX | CREATE INDEX index_name ON table_name (column_name) or CREATE UNIQUE INDEX index_name |
| CREATE VIEW | CREATE VIEW view_name AS SELECT column_name(s) FROM table_name WHERE condition |
| DELETE | DELETE FROM table_name WHERE some_column=some_value or DELETE FROM table_name DELETE * FROM table_name |
| DROP DATABASE | DROP DATABASE database_name |
| DROP INDEX | DROP INDEX table_name.index_name (SQL Server) DROP INDEX index_name ON table_name (MS Access) DROP INDEX index_name (DB2/Oracle) ALTER TABLE table_name DROP INDEX index_name (MySQL) |
| DROP TABLE | DROP TABLE table_name |
| GROUP BY | SELECT column_name, aggregate_function(column_name) FROM table_name WHERE column_name operator value GROUP BY column_name |
| HAVING | SELECT column_name, aggregate_function(column_name) FROM table_name WHERE column_name operator value GROUP BY column_name HAVING aggregate_function(column_name) operator value |
| IN | SELECT column_name(s) FROM table_name WHERE column_name IN (value1,value2,..) |
| INSERT INTO | INSERT INTO table_name VALUES (value1, value2, value3,....) or INSERT INTO table_name |
| INNER JOIN | SELECT column_name(s) FROM table_name1 INNER JOIN table_name2 ON table_name1.column_name=table_name2.column_name |
| LEFT JOIN | SELECT column_name(s) FROM table_name1 LEFT JOIN table_name2 ON table_name1.column_name=table_name2.column_name |
| RIGHT JOIN | SELECT column_name(s) FROM table_name1 RIGHT JOIN table_name2 ON table_name1.column_name=table_name2.column_name |
| FULL JOIN | SELECT column_name(s) FROM table_name1 FULL JOIN table_name2 ON table_name1.column_name=table_name2.column_name |
| LIKE | SELECT column_name(s) FROM table_name WHERE column_name LIKE pattern |
| ORDER BY | SELECT column_name(s) FROM table_name ORDER BY column_name [ASC|DESC] |
| SELECT | SELECT column_name(s) FROM table_name |
| SELECT * | SELECT * FROM table_name |
| SELECT DISTINCT | SELECT DISTINCT column_name(s) FROM table_name |
| SELECT INTO | SELECT * INTO new_table_name [IN externaldatabase] FROM old_table_name or SELECT column_name(s) |
| SELECT TOP | SELECT TOP number|percent column_name(s) FROM table_name |
| TRUNCATE TABLE | TRUNCATE TABLE table_name |
| UNION | SELECT column_name(s) FROM table_name1 UNION SELECT column_name(s) FROM table_name2 |
| UNION ALL | SELECT column_name(s) FROM table_name1 UNION ALL SELECT column_name(s) FROM table_name2 |
| UPDATE | UPDATE table_name SET column1=value, column2=value,... WHERE some_column=some_value |
| WHERE | SELECT column_name(s) FROM table_name WHERE column_name operator value |
Select Statement
SELECT "column_name" FROM "table_name"
Distinct
SELECT DISTINCT "column_name"
FROM "table_name"
Where
SELECT "column_name"
FROM "table_name"
WHERE "condition"
And/Or
SELECT "column_name"
FROM "table_name"
WHERE "simple condition"
{[AND|OR] "simple condition"}+
In
SELECT "column_name"
FROM "table_name"
WHERE "column_name" IN ('value1', 'value2', ...)
Between
SELECT "column_name"
FROM "table_name"
WHERE "column_name" BETWEEN 'value1' AND 'value2'
Like
SELECT "column_name"
FROM "table_name"
WHERE "column_name" LIKE {PATTERN}
Order By
SELECT "column_name"
FROM "table_name"
[WHERE "condition"]
ORDER BY "column_name" [ASC, DESC]
Count
SELECT COUNT("column_name")
FROM "table_name"
Group By
SELECT "column_name1", SUM("column_name2")
FROM "table_name"
GROUP BY "column_name1"
Having
SELECT "column_name1", SUM("column_name2")
FROM "table_name"
GROUP BY "column_name1"
HAVING (arithematic function condition)
Create Table Statement
CREATE TABLE "table_name"
("column 1" "data_type_for_column_1",
"column 2" "data_type_for_column_2",
... )
Drop Table Statement
DROP TABLE "table_name"
Truncate Table Statement
TRUNCATE TABLE "table_name"
Insert Into Statement
INSERT INTO "table_name" ("column1", "column2", ...)
VALUES ("value1", "value2", ...)
Update Statement
UPDATE "table_name"
SET "column_1" = [new value]
WHERE {condition}
Delete From Statement
DELETE FROM "table_name"
WHERE {condition}
Wednesday, February 4, 2009
எளிய தமிழில் SQL - பாகம் 13
Primary key மற்றும் Foreign key ஆகியவற்றைப் பற்றியும், SQL வாயிலாக இரண்டு Tableகளை இணைப்பது எப்படி என்றும் இன்றைக்குப் பார்ப்போம்.
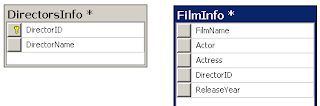
Primary key என்பது ஒரு Tableல் இருக்கும் அனைத்து Row களையும் தனித்தனியாகக் கண்டறிய உதவுகிறது. உதாரணமாக ஒரு எளிய Table. அதில் 2 Columns மட்டும். அவை DirectorID int, DirectorName varchar(50)
(மேலும் இது Primary keyஆகவும், Autoincrement ஆகவும் கொடுக்கப்படுகிறது. Auto increment என்பது int எனப்படும் எண்களுக்கு மட்டுமே சாத்தியப்படும்) , இந்த Tableக்கு DirectorInfo எனப் பெயரிடுவோம்.

இந்த DirectorID எனப்படும் Column ஐ Primary key ஆக மாற்ற என்ன செய்யவேண்டும்.
DirectorID எனப்படும் Column ஐத் தேர்வு செய்து Right Click செய்து, தோன்றக்கூடிய சிறு menuவில் Set Primary Key என்பதைச் சொடுக்கவும்.
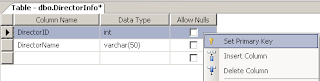 இதைச் செய்தபிறகு DirectorID க்கு இடது புறம் ஒரு சிறிய சாவியின் படம் தெரிய ஆரம்பிக்கும்.
இதைச் செய்தபிறகு DirectorID க்கு இடது புறம் ஒரு சிறிய சாவியின் படம் தெரிய ஆரம்பிக்கும்.
மேலும் Identity Column ( Auto increment) ஆக மாற்றுவதற்கு என்ன செய்வது?
DirectorID எனப்படும் Column ஐத் தேர்வு செய்து F4 என்னும் Function keyஐ அழுத்தினால் Properties Windows ஐக் காணலாம். அதில் Table Designer என்னும் தலைப்பின் கீழே, Identity Column என்பதற்கு நேராக உள்ள Drop Downlist ல் DirectorID என்பதைத் தேர்வு செய்யவும்.
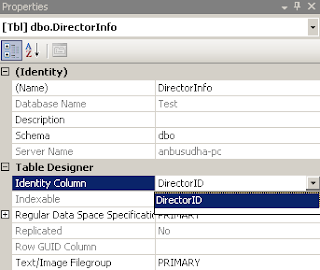 அல்லது கீழ்க்கண்ட செயல்முறையைத் தொடரலாம். Identity Column ஆக மாற்ற கீழ்க்கண்ட படத்தில் உள்ளபடி செய்யலாம். அந்த Column ஐத் தேர்வுசெய்தபிறகு, கீழே உள்ள Column Properties Tab ல் , Identity Specification ஐ Yes எனக் கொடுக்கவும்.
அல்லது கீழ்க்கண்ட செயல்முறையைத் தொடரலாம். Identity Column ஆக மாற்ற கீழ்க்கண்ட படத்தில் உள்ளபடி செய்யலாம். அந்த Column ஐத் தேர்வுசெய்தபிறகு, கீழே உள்ள Column Properties Tab ல் , Identity Specification ஐ Yes எனக் கொடுக்கவும்.
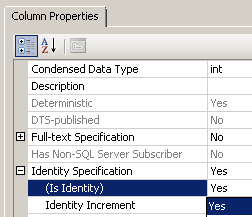 அதன் Increment , seed மதிப்புகளைக் கொடுக்கலாம். அல்லது 1 எனவே விட்டுவிடலாம். ஒவ்வொரு rowன் மதிப்பும் ஐந்து, ஐந்தாக அதிகரிக்கவேண்டும் எனில் Identity Increment ன் மதிப்பை 5 எனக் கொடுக்கவும்.
அதன் Increment , seed மதிப்புகளைக் கொடுக்கலாம். அல்லது 1 எனவே விட்டுவிடலாம். ஒவ்வொரு rowன் மதிப்பும் ஐந்து, ஐந்தாக அதிகரிக்கவேண்டும் எனில் Identity Increment ன் மதிப்பை 5 எனக் கொடுக்கவும்.
சரி ஒருவழியாக DirectorsInfo வின் Structure ஐ உருவாக்கிவிட்டோம். இப்போது இதை Close செய்துவிடவும்.
 இப்போது மேலும் ஒரு எளிய Table ஒன்றை உருவாக்கி, அதற்கு FilmInfo எனப் பெயரிடுவோம்.
இப்போது மேலும் ஒரு எளிய Table ஒன்றை உருவாக்கி, அதற்கு FilmInfo எனப் பெயரிடுவோம்.
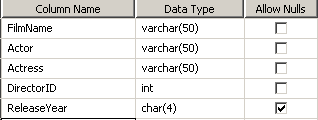 இந்த FilmInfo என்கிற புதிய Tableல் DirectorID என்னும் Column உள்ளது. இது int எனப்படும் எண் வகையைச் சேர்ந்த Data Type.
இந்த FilmInfo என்கிற புதிய Tableல் DirectorID என்னும் Column உள்ளது. இது int எனப்படும் எண் வகையைச் சேர்ந்த Data Type.
ஒவ்வொரு படத்தையும் வேறு வேறு இயக்குநர்கள் இயக்கியிருக்கலாம். ஒன்றுக்கு மேற்பட்ட திரைப்படங்களை ஒரே இயக்குநரே இயக்கியிருக்கலாம்.
1000 திரைப்படங்களின் தகவல்களைச் சேகரித்தோம் எனில், அதில் ஒரே இயக்குநரானவர் 10 அல்லது 25 அல்லது 100 படங்களைக்கூட எடுத்திருப்பார். 100 முறை அவரது பெயரை எழுதினால் நினைவகம் (memory) தேவையில்லாமல் ஆக்கிரமிக்கப்படும். அதனால் அவரது பெயரை ஒரே ஒருமுறை மட்டும் Master Table ல் (இங்கே DirectorsInfo - என்பதே Master table) கொடுத்து அவருக்காக ஒரு எண்ணை ஒதுக்கி விடுகிறோம்.
பலவித திரைப்படங்களின் தகவல்களை இரண்டாவது Table (FilmInfo என்பது இங்கே Detail Table)ல் பதிவுசெய்யப் போகிறோம். இங்கே ஒவ்வொரு Directorன் பெயரை முழுவதும் எழுதி நினைவகத்தை ஆக்கிரமிக்காமல் அவருக்குரிய எண்ணை மட்டும் கொடுப்போம்.
Master Table ல் ஒவ்வொரு Director க்கும் எண்களும், பெயர்களும் கொடுத்துவிட்டு, Detail Tableல் Directorக்கு உரிய எண்ணை மட்டும் கொடுப்பது வழக்கம்.
நினைவக இழப்பைக் குறைப்பதற்காகவும், ஒரே தகவலை திரும்பத்திரும்ப எழுதுவதைத் தவிர்க்கவும் - இந்த ஏற்பாடு.
ஒரு Director ஆனவர் பல படங்களை எடுத்துள்ளார் - எனில் இதை ONE TO MANY RELATIONSHIP என்போம்.
இந்த இரண்டாவது Tableன் Structureஐ ஏற்றிமுடித்ததும் கீழ்க்கண்ட செயல்முறையைச் செய்து இரண்டு Tableகளுக்கும் ஒரு உறவுமுறையை உண்டாக்கவும். உறவுமுறை (Table Relationship).
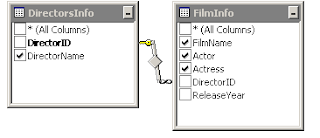
Test எனப்படும் Databaseல் Database Diagrams என்பதைத் தேர்வுசெய்து, Right Click செய்து, அதில் New Database Diagram ஐத் தேர்ந்தெடுக்கவும்.
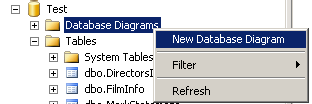
உடன் தெரியும் உரையாடல் பெட்டியில் (dialog box) , DirectorsInfo மற்றும், FilmInfo ஆகிய இரண்டு Tableகளையும் தேர்வு செய்து , Add ஐ அழுத்தியபிறகு, Close அழுத்தவும்.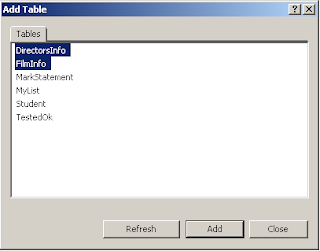 இப்போது திரை கீழ்க்கண்டவாறு காட்சியளிக்கும்.
இப்போது திரை கீழ்க்கண்டவாறு காட்சியளிக்கும்.
 DirectorsInfo ல் இருக்கும் DirectorID ஐ அப்படியே இழுத்துக்கொண்டு வந்து, FilmInfo வில் இருக்கும் DirectorIDல் விடவும். அதாவது Master Tableன் DirectorID ஐ Drag செய்து, Detail Table ல் இருக்கும் DirectorIDல் Drop செய்யவும்.
DirectorsInfo ல் இருக்கும் DirectorID ஐ அப்படியே இழுத்துக்கொண்டு வந்து, FilmInfo வில் இருக்கும் DirectorIDல் விடவும். அதாவது Master Tableன் DirectorID ஐ Drag செய்து, Detail Table ல் இருக்கும் DirectorIDல் Drop செய்யவும்.
எளிதான Drag and Drop தான்.
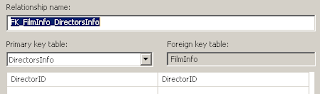
இப்போது திரையில் மேற்கண்ட படம் தெரியும். Primary key Table (Director Info).
Foreign Key Table (FilmInfo). இரண்டுமே DirectorID என்னும் Column ஆகவும், ஒரே DataTypeஆகவும் இருக்கிறது. பிறகு இரண்டு முறை OK கொடுக்கவும்.
இப்போது திரையில் கீழ்க்கண்ட படத்தைக் காணலாம்.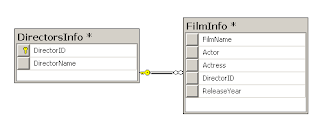 இந்த Database Diagram ஐ Close செய்துவிட்டு, Tableக்குரிய தகவல்களை ஒவ்வொரு Row ஆக ஏற்றவும்.
இந்த Database Diagram ஐ Close செய்துவிட்டு, Tableக்குரிய தகவல்களை ஒவ்வொரு Row ஆக ஏற்றவும்.
DirectorsInfo வில் முதலில் உங்களுக்குத் தெரிந்த Directorsன் பெயர்களை மட்டும் கொடுத்தால் போதும். DirectorID என்பது அதுவாகவே உருவாகிக்கொள்ளும். அடுத்தடுத்த Directorகளுக்குரிய எண்கள் தானாகவே அமைந்துகொள்ளும். இதற்கு காரணம் அந்த குறிப்பிட்ட Column ஆனது IDENTITY Column என அமைக்கப்பட்டுள்ளதே.
பிறகு ஒவ்வொரு படங்களுக்கும் உரிய தகவல்களை Row by Row வாக FilmInfo என்னும் Tableல் ஏற்றவும். இங்கே DirectorIDஎன்னும் Columnல் ஏற்கனவே Master Tableல் என்ன எண்கள் அளிக்கப்பட்டிருக்கிறதோ அவற்றை மாத்திரமே கொடுக்கவேண்டும். Master Tableல் இல்லாத DirectorID ஐக் கொடுத்தால் பிழைச்செய்தி காண்பிக்கும்.
உதாரணத்திற்காக DirectorInfoவில் சில records உங்கள் பார்வைக்கு.
 FilmInfo எனப்படும் Detail Tableல் நான் ஏற்றிய சில Records கீழே.
FilmInfo எனப்படும் Detail Tableல் நான் ஏற்றிய சில Records கீழே.
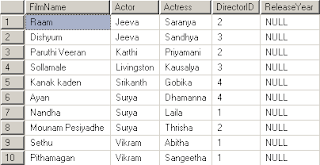 இதில் Master Table ல் என்ன DirectorID கொடுத்தோமோ அதை Detail Tableல் refer செய்கிறோம். ஒவ்வொரு படத்துக்கும் அதை இயக்கிய இயக்குநரின் பெயரைக் கொடுக்காமல், அவருக்குரிய ID எனப்படும் எண்ணை மட்டும் கொடுக்கிறோம்.
இதில் Master Table ல் என்ன DirectorID கொடுத்தோமோ அதை Detail Tableல் refer செய்கிறோம். ஒவ்வொரு படத்துக்கும் அதை இயக்கிய இயக்குநரின் பெயரைக் கொடுக்காமல், அவருக்குரிய ID எனப்படும் எண்ணை மட்டும் கொடுக்கிறோம்.
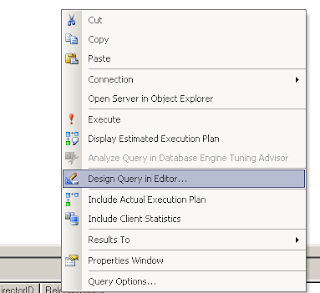
இரண்டு Tableஐயும் இணைத்து JOIN செய்வதற்கு உரிய செயல்முறை கீழே:
T-SQL Editorல் Right Click செய்து, Design Query in Editor என்பதைத் தேர்வு செய்யவும்.
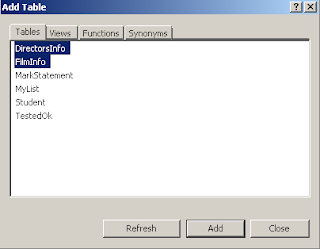
பிறகு வரும் Dialog boxல் இரண்டு Tablesஐயும் தேர்வு செய்து Add கொடுத்தபின் Close செய்யவும்.
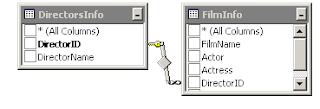
 ஏற்கனவே Primary key, மற்றும் Foreign key ஆகியவை முறைப்படி இணைக்கப்பட்டிருந்தால் கீழ்க்கண்ட படம் திரையில் காட்சியளிக்கும்.
ஏற்கனவே Primary key, மற்றும் Foreign key ஆகியவை முறைப்படி இணைக்கப்பட்டிருந்தால் கீழ்க்கண்ட படம் திரையில் காட்சியளிக்கும்.
 இரண்டு Tableகளிலிருந்து எந்தெந்த Columnsஐ நாம் தேர்ந்தெடுக்கிறோம் என்பதை ஒவ்வொரு Columnக்கும் எதிரேயுள்ள Checkbox ல் Tick செய்துவிடுங்கள்.
இரண்டு Tableகளிலிருந்து எந்தெந்த Columnsஐ நாம் தேர்ந்தெடுக்கிறோம் என்பதை ஒவ்வொரு Columnக்கும் எதிரேயுள்ள Checkbox ல் Tick செய்துவிடுங்கள்.
 இப்படி Columnகளைத் தேர்வுசெய்தவுடன் உங்களுக்குக் கீழ்க்கண்ட Query கிடைக்கும்
இப்படி Columnகளைத் தேர்வுசெய்தவுடன் உங்களுக்குக் கீழ்க்கண்ட Query கிடைக்கும்
SELECT DirectorsInfo.DirectorName, FilmInfo.FilmName, FilmInfo.Actor, FilmInfo.Actress
FROM DirectorsInfo INNER JOIN
FilmInfo ON DirectorsInfo.DirectorID = FilmInfo.DirectorID
பின் OK அழுத்தினால் மேலேயுள்ள Query ஆனது T-SQL Editorக்கு வந்துவிடும்.
F5 அழுத்தின் இயக்கவும். இதன் மூலம் இரண்டு Tableன் தகவல்களும் ஒரே திரையில் காண்பிக்கப்படும்.
Primary key என்பது ஒரு Tableல் இருக்கும் அனைத்து Row களையும் தனித்தனியாகக் கண்டறிய உதவுகிறது. உதாரணமாக ஒரு எளிய Table. அதில் 2 Columns மட்டும். அவை DirectorID int, DirectorName varchar(50)
(மேலும் இது Primary keyஆகவும், Autoincrement ஆகவும் கொடுக்கப்படுகிறது. Auto increment என்பது int எனப்படும் எண்களுக்கு மட்டுமே சாத்தியப்படும்) , இந்த Tableக்கு DirectorInfo எனப் பெயரிடுவோம்.

இந்த DirectorID எனப்படும் Column ஐ Primary key ஆக மாற்ற என்ன செய்யவேண்டும்.
DirectorID எனப்படும் Column ஐத் தேர்வு செய்து Right Click செய்து, தோன்றக்கூடிய சிறு menuவில் Set Primary Key என்பதைச் சொடுக்கவும்.
 இதைச் செய்தபிறகு DirectorID க்கு இடது புறம் ஒரு சிறிய சாவியின் படம் தெரிய ஆரம்பிக்கும்.
இதைச் செய்தபிறகு DirectorID க்கு இடது புறம் ஒரு சிறிய சாவியின் படம் தெரிய ஆரம்பிக்கும்.மேலும் Identity Column ( Auto increment) ஆக மாற்றுவதற்கு என்ன செய்வது?
DirectorID எனப்படும் Column ஐத் தேர்வு செய்து F4 என்னும் Function keyஐ அழுத்தினால் Properties Windows ஐக் காணலாம். அதில் Table Designer என்னும் தலைப்பின் கீழே, Identity Column என்பதற்கு நேராக உள்ள Drop Downlist ல் DirectorID என்பதைத் தேர்வு செய்யவும்.
 அல்லது கீழ்க்கண்ட செயல்முறையைத் தொடரலாம். Identity Column ஆக மாற்ற கீழ்க்கண்ட படத்தில் உள்ளபடி செய்யலாம். அந்த Column ஐத் தேர்வுசெய்தபிறகு, கீழே உள்ள Column Properties Tab ல் , Identity Specification ஐ Yes எனக் கொடுக்கவும்.
அல்லது கீழ்க்கண்ட செயல்முறையைத் தொடரலாம். Identity Column ஆக மாற்ற கீழ்க்கண்ட படத்தில் உள்ளபடி செய்யலாம். அந்த Column ஐத் தேர்வுசெய்தபிறகு, கீழே உள்ள Column Properties Tab ல் , Identity Specification ஐ Yes எனக் கொடுக்கவும். அதன் Increment , seed மதிப்புகளைக் கொடுக்கலாம். அல்லது 1 எனவே விட்டுவிடலாம். ஒவ்வொரு rowன் மதிப்பும் ஐந்து, ஐந்தாக அதிகரிக்கவேண்டும் எனில் Identity Increment ன் மதிப்பை 5 எனக் கொடுக்கவும்.
அதன் Increment , seed மதிப்புகளைக் கொடுக்கலாம். அல்லது 1 எனவே விட்டுவிடலாம். ஒவ்வொரு rowன் மதிப்பும் ஐந்து, ஐந்தாக அதிகரிக்கவேண்டும் எனில் Identity Increment ன் மதிப்பை 5 எனக் கொடுக்கவும்.சரி ஒருவழியாக DirectorsInfo வின் Structure ஐ உருவாக்கிவிட்டோம். இப்போது இதை Close செய்துவிடவும்.
 இப்போது மேலும் ஒரு எளிய Table ஒன்றை உருவாக்கி, அதற்கு FilmInfo எனப் பெயரிடுவோம்.
இப்போது மேலும் ஒரு எளிய Table ஒன்றை உருவாக்கி, அதற்கு FilmInfo எனப் பெயரிடுவோம். இந்த FilmInfo என்கிற புதிய Tableல் DirectorID என்னும் Column உள்ளது. இது int எனப்படும் எண் வகையைச் சேர்ந்த Data Type.
இந்த FilmInfo என்கிற புதிய Tableல் DirectorID என்னும் Column உள்ளது. இது int எனப்படும் எண் வகையைச் சேர்ந்த Data Type.ஒவ்வொரு படத்தையும் வேறு வேறு இயக்குநர்கள் இயக்கியிருக்கலாம். ஒன்றுக்கு மேற்பட்ட திரைப்படங்களை ஒரே இயக்குநரே இயக்கியிருக்கலாம்.
1000 திரைப்படங்களின் தகவல்களைச் சேகரித்தோம் எனில், அதில் ஒரே இயக்குநரானவர் 10 அல்லது 25 அல்லது 100 படங்களைக்கூட எடுத்திருப்பார். 100 முறை அவரது பெயரை எழுதினால் நினைவகம் (memory) தேவையில்லாமல் ஆக்கிரமிக்கப்படும். அதனால் அவரது பெயரை ஒரே ஒருமுறை மட்டும் Master Table ல் (இங்கே DirectorsInfo - என்பதே Master table) கொடுத்து அவருக்காக ஒரு எண்ணை ஒதுக்கி விடுகிறோம்.
பலவித திரைப்படங்களின் தகவல்களை இரண்டாவது Table (FilmInfo என்பது இங்கே Detail Table)ல் பதிவுசெய்யப் போகிறோம். இங்கே ஒவ்வொரு Directorன் பெயரை முழுவதும் எழுதி நினைவகத்தை ஆக்கிரமிக்காமல் அவருக்குரிய எண்ணை மட்டும் கொடுப்போம்.
Master Table ல் ஒவ்வொரு Director க்கும் எண்களும், பெயர்களும் கொடுத்துவிட்டு, Detail Tableல் Directorக்கு உரிய எண்ணை மட்டும் கொடுப்பது வழக்கம்.
நினைவக இழப்பைக் குறைப்பதற்காகவும், ஒரே தகவலை திரும்பத்திரும்ப எழுதுவதைத் தவிர்க்கவும் - இந்த ஏற்பாடு.
ஒரு Director ஆனவர் பல படங்களை எடுத்துள்ளார் - எனில் இதை ONE TO MANY RELATIONSHIP என்போம்.
இந்த இரண்டாவது Tableன் Structureஐ ஏற்றிமுடித்ததும் கீழ்க்கண்ட செயல்முறையைச் செய்து இரண்டு Tableகளுக்கும் ஒரு உறவுமுறையை உண்டாக்கவும். உறவுமுறை (Table Relationship).
Test எனப்படும் Databaseல் Database Diagrams என்பதைத் தேர்வுசெய்து, Right Click செய்து, அதில் New Database Diagram ஐத் தேர்ந்தெடுக்கவும்.

உடன் தெரியும் உரையாடல் பெட்டியில் (dialog box) , DirectorsInfo மற்றும், FilmInfo ஆகிய இரண்டு Tableகளையும் தேர்வு செய்து , Add ஐ அழுத்தியபிறகு, Close அழுத்தவும்.
 இப்போது திரை கீழ்க்கண்டவாறு காட்சியளிக்கும்.
இப்போது திரை கீழ்க்கண்டவாறு காட்சியளிக்கும். DirectorsInfo ல் இருக்கும் DirectorID ஐ அப்படியே இழுத்துக்கொண்டு வந்து, FilmInfo வில் இருக்கும் DirectorIDல் விடவும். அதாவது Master Tableன் DirectorID ஐ Drag செய்து, Detail Table ல் இருக்கும் DirectorIDல் Drop செய்யவும்.
DirectorsInfo ல் இருக்கும் DirectorID ஐ அப்படியே இழுத்துக்கொண்டு வந்து, FilmInfo வில் இருக்கும் DirectorIDல் விடவும். அதாவது Master Tableன் DirectorID ஐ Drag செய்து, Detail Table ல் இருக்கும் DirectorIDல் Drop செய்யவும்.எளிதான Drag and Drop தான்.

இப்போது திரையில் மேற்கண்ட படம் தெரியும். Primary key Table (Director Info).
Foreign Key Table (FilmInfo). இரண்டுமே DirectorID என்னும் Column ஆகவும், ஒரே DataTypeஆகவும் இருக்கிறது. பிறகு இரண்டு முறை OK கொடுக்கவும்.
இப்போது திரையில் கீழ்க்கண்ட படத்தைக் காணலாம்.
 இந்த Database Diagram ஐ Close செய்துவிட்டு, Tableக்குரிய தகவல்களை ஒவ்வொரு Row ஆக ஏற்றவும்.
இந்த Database Diagram ஐ Close செய்துவிட்டு, Tableக்குரிய தகவல்களை ஒவ்வொரு Row ஆக ஏற்றவும்.DirectorsInfo வில் முதலில் உங்களுக்குத் தெரிந்த Directorsன் பெயர்களை மட்டும் கொடுத்தால் போதும். DirectorID என்பது அதுவாகவே உருவாகிக்கொள்ளும். அடுத்தடுத்த Directorகளுக்குரிய எண்கள் தானாகவே அமைந்துகொள்ளும். இதற்கு காரணம் அந்த குறிப்பிட்ட Column ஆனது IDENTITY Column என அமைக்கப்பட்டுள்ளதே.
பிறகு ஒவ்வொரு படங்களுக்கும் உரிய தகவல்களை Row by Row வாக FilmInfo என்னும் Tableல் ஏற்றவும். இங்கே DirectorIDஎன்னும் Columnல் ஏற்கனவே Master Tableல் என்ன எண்கள் அளிக்கப்பட்டிருக்கிறதோ அவற்றை மாத்திரமே கொடுக்கவேண்டும். Master Tableல் இல்லாத DirectorID ஐக் கொடுத்தால் பிழைச்செய்தி காண்பிக்கும்.
உதாரணத்திற்காக DirectorInfoவில் சில records உங்கள் பார்வைக்கு.
 FilmInfo எனப்படும் Detail Tableல் நான் ஏற்றிய சில Records கீழே.
FilmInfo எனப்படும் Detail Tableல் நான் ஏற்றிய சில Records கீழே. இதில் Master Table ல் என்ன DirectorID கொடுத்தோமோ அதை Detail Tableல் refer செய்கிறோம். ஒவ்வொரு படத்துக்கும் அதை இயக்கிய இயக்குநரின் பெயரைக் கொடுக்காமல், அவருக்குரிய ID எனப்படும் எண்ணை மட்டும் கொடுக்கிறோம்.
இதில் Master Table ல் என்ன DirectorID கொடுத்தோமோ அதை Detail Tableல் refer செய்கிறோம். ஒவ்வொரு படத்துக்கும் அதை இயக்கிய இயக்குநரின் பெயரைக் கொடுக்காமல், அவருக்குரிய ID எனப்படும் எண்ணை மட்டும் கொடுக்கிறோம்.இரண்டு Tableஐயும் இணைத்து JOIN செய்வதற்கு உரிய செயல்முறை கீழே:
T-SQL Editorல் Right Click செய்து, Design Query in Editor என்பதைத் தேர்வு செய்யவும்.

பிறகு வரும் Dialog boxல் இரண்டு Tablesஐயும் தேர்வு செய்து Add கொடுத்தபின் Close செய்யவும்.
 ஏற்கனவே Primary key, மற்றும் Foreign key ஆகியவை முறைப்படி இணைக்கப்பட்டிருந்தால் கீழ்க்கண்ட படம் திரையில் காட்சியளிக்கும்.
ஏற்கனவே Primary key, மற்றும் Foreign key ஆகியவை முறைப்படி இணைக்கப்பட்டிருந்தால் கீழ்க்கண்ட படம் திரையில் காட்சியளிக்கும். இரண்டு Tableகளிலிருந்து எந்தெந்த Columnsஐ நாம் தேர்ந்தெடுக்கிறோம் என்பதை ஒவ்வொரு Columnக்கும் எதிரேயுள்ள Checkbox ல் Tick செய்துவிடுங்கள்.
இரண்டு Tableகளிலிருந்து எந்தெந்த Columnsஐ நாம் தேர்ந்தெடுக்கிறோம் என்பதை ஒவ்வொரு Columnக்கும் எதிரேயுள்ள Checkbox ல் Tick செய்துவிடுங்கள். இப்படி Columnகளைத் தேர்வுசெய்தவுடன் உங்களுக்குக் கீழ்க்கண்ட Query கிடைக்கும்
இப்படி Columnகளைத் தேர்வுசெய்தவுடன் உங்களுக்குக் கீழ்க்கண்ட Query கிடைக்கும்SELECT DirectorsInfo.DirectorName, FilmInfo.FilmName, FilmInfo.Actor, FilmInfo.Actress
FROM DirectorsInfo INNER JOIN
FilmInfo ON DirectorsInfo.DirectorID = FilmInfo.DirectorID
பின் OK அழுத்தினால் மேலேயுள்ள Query ஆனது T-SQL Editorக்கு வந்துவிடும்.
F5 அழுத்தின் இயக்கவும். இதன் மூலம் இரண்டு Tableன் தகவல்களும் ஒரே திரையில் காண்பிக்கப்படும்.

Tuesday, February 3, 2009
எளிய தமிழில் SQL - பாகம் 12
SELECT உடன் ஒரு செயல்முறைப் பயிற்சி
SELECT * FROM tableName என்பது ஒரு Tableல் இருக்கும் அனைத்து Rowsஐயும் திரையில் காண்பிக்க, தேடி எடுக்க.
இதில் குறிப்பிட்ட Rowsஐ மாத்திரம் எடுப்பதற்கு என்ன செய்யவேண்டும். ஒரு WHERE ஐ இணைத்தால் போதும்.
SELECT * FROM tableName WHERE Condition
Condition என்பதைக் கட்டுப்பாடு எனக் கொண்டால் ஒன்றுக்கு மேற்பட்ட கட்டுப்பாடுகளை விதிக்க என்ன செய்ய வேண்டும்?
SELECT * FROM tableName WHERE Condition1 AND Condition2 AND Condition3
AND என்னும் Logical Operator ஐ உடன் சேர்த்துப் பயன்படுத்த வேண்டும்.
SELECT * FROM என்று கொடுத்தால் அனைத்து Columns ஐயும் நாம் பார்ப்பதற்காக தேர்வு செய்கிறோம் என்று அர்த்தம்.
இதில் குறிப்பிட்ட Columnsஐ மாத்திரம் பார்க்கவேண்டுமென்றால் என்ன செய்வது?
SELECT Column1, Column2, Column3 FROM tableName
SELECT column_name(s) FROM table_name
உதாரணம்:
SELECT [Name], [City] FROM Persons
கீழ்க்கண்ட Tableன் தகவல்களை உற்று நோக்கவும். இதில் City என்னும் இடத்தில் 3 நகரங்கள் உள்ளன. Chennai, Erode, USA. ஆனால் Chennai,Erode ஆகியவை இரண்டுமுறையும், USA - ஒருமுறையும் இடம் பெற்றுள்ளது.
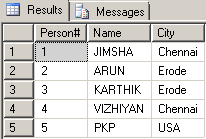
SELECT [CITY] FROM MyList எனக் கொடுத்தால் அனைத்து நகரங்களும் வரும்.
ஆனால் இதில் திரும்பத்திரும்ப வரும் நகரங்களை விட்டுவிட்டு, ஒன்றுக்கு மேற்பட்டு வந்திருப்பவைகளை ஒரே ஒரு முறை மட்டும் காண்பிப்பதற்கு DISTINCT உதவும்.
SELECT DISTINCT [CITY] FROM MyList
 குறிப்பிட்ட நகரத்தை மட்டும் காண்பதற்கு இதில் WHERE பயன்படுத்துவோம்.
குறிப்பிட்ட நகரத்தை மட்டும் காண்பதற்கு இதில் WHERE பயன்படுத்துவோம்.SELECT column_name(s)இதையே வேறு விதமாக OR பயன்படுத்தாமல் எழுதலாம். அதற்கு IN பயன்படுத்தவேண்டும்.
FROM table_name
WHERE column_name operator value
SELECT * FROM MyList WHERE City ='Erode'
ஈரோடு நகர் நண்பர்களைப் பற்றி மட்டும் காண்பதற்குநமது தேர்வில் ஒன்றுக்குமேற்பட்ட நகரத்தைக் காண்பதற்கு OR பயன்படுத்துவோம்
அமெரிக்கா மற்றும், சென்னை - இவற்றைத் தேர்வு செய்வதற்கு :
SELECT * FROM MyList WHERE City ='USA' OR City = 'Chennai'


SELECT * FROM MyList WHERE City IN ('USA' ,'Chennai')
இதற்கும் அதே விடைதான்.
சென்னை நீங்கலாக உள்ள நகரங்களில் இருக்கும் நண்பர்களின் பட்டியலைப் பார்வையிட:
இதற்கு NOT பயன்படுத்தலாம். NOT என்பது Logical Operator வகையைச் சார்ந்தது.
<> , != என்பது Relational Operator வகையைச் சேர்ந்தது.
அ) SELECT * FROM MyList WHERE City <> 'Chennai'
ஆ) SELECT * FROM MyList WHERE City != 'Chennai'
இ) SELECT * FROM MyList WHERE City NOT IN ('Chennai')
அனைத்துக்கும் ஒரே விடைதான். அது கீழே. சென்னையைத் தவிர.
 யாருடைய பெயரில் n என்கிற எழுத்து உள்ளது என்பதை அறிவதற்கு :
யாருடைய பெயரில் n என்கிற எழுத்து உள்ளது என்பதை அறிவதற்கு :SELECT * FROM MyList WHERE [Name] LIKE '%n%'
 LIKE எனப்படும் keywordன் பயன் யாதெனில், குறிப்பிட்ட எழுத்துகளைக் கொண்ட தகவல்களை மட்டும் தேர்வு செய்வது
LIKE எனப்படும் keywordன் பயன் யாதெனில், குறிப்பிட்ட எழுத்துகளைக் கொண்ட தகவல்களை மட்டும் தேர்வு செய்வது%n% எனில் ஏதோ ஒரு எழுத்து n ஆக இருக்கும் நபர்கள்.
_ என்பது underscore (அடிக்கோடு), இது ஒரு எழுத்தை மட்டும் எதைக்கொண்டாவது நிரப்பிக்கொள் என்பதற்காக. % என்பது மீதமுள்ள அனைத்து எழுத்துக்களையும் நிரப்பிக்கொள் என்பதே. இவற்றிற்கு Wild Card Characters என்று பெயர்.
SELECT * FROM MyList WHERE [Name] LIKE '_a%'
முதல் எழுத்து எதுவாக இருந்தாலும் பரவாயில்லை. ஆனால் இரண்டாம் எழுத்து கண்டிப்பாக 'a'. மீதியுள்ள எழுத்துக்களைப் பற்றிக் கவலையில்லை. அதற்காக.
சுருங்கச் சொன்னால் யாருடைய பெயரில், இரண்டாம் எழுத்து a ஆக இருக்கிறது.
SELECT * FROM MyList WHERE [Person#] = 1 OR [Person#] = 2 OR [Person#] = 3
 OR என்பது எதாவது ஒரு Condition ஏற்றுக்கொண்டாலும் ஒத்துழைக்கக்கூடியது
OR என்பது எதாவது ஒரு Condition ஏற்றுக்கொண்டாலும் ஒத்துழைக்கக்கூடியதுஇதை IN மூலம் எழுதினால்,
SELECT * FROM MyList WHERE [Person#] IN (1,3,5)
1,3,5 இவற்றைத் தவிர பிற Rowsகளைப் பார்க்க :
அதாவது 2, மற்றும் 4 ஆகியவற்றை மட்டும் பார்க்க
SELECT * FROM MyList WHERE [Person#] NOT IN (1,3,5)
அல்லது
SELECT * FROM MyList WHERE [Person#] != 1 AND [Person#] != 3 AND [Person#] !=5
அல்லது
SELECT * FROM MyList WHERE [Person#] <> 1 AND [Person#] <> 3 AND [Person#] <> 5
 SELECT * FROM MyList எனக் கொடுக்கிறேன்.
SELECT * FROM MyList எனக் கொடுக்கிறேன்.இதன் விடை
 இதில் பெயர்களை மையமாகக் கொண்டு ஏறுவரிசை (ascending), அல்லது இறங்குவரிசை (descending) ஆகக் காண்பிப்பதற்கு என்ன செய்வது?
இதில் பெயர்களை மையமாகக் கொண்டு ஏறுவரிசை (ascending), அல்லது இறங்குவரிசை (descending) ஆகக் காண்பிப்பதற்கு என்ன செய்வது?இதற்காக SELECT உடன் ORDER BY எனப்படும் keyword ஐப் பயன்படுத்தவேண்டும்.
ASC எனக் கொடுத்தால் ஏறுவரிசையாகவும், DESC எனக் கொடுத்தால் இறங்குவரிசையாகவும் காட்சியளிக்கும்.
SELECT * FROM MyList ORDER BY [Name] ASC (ஏறுவரிசையில் பார்க்க)
 SELECT * FROM MyList ORDER BY [Name] DESC (இறங்குவரிசையில் காண)
SELECT * FROM MyList ORDER BY [Name] DESC (இறங்குவரிசையில் காண)
Subscribe to:
Posts (Atom)